
Scaling SaaS Products: A Developer's Guide to Growth
This article was inspired by a trending topic from Dev.to
View original discussionBuilding Scalable SaaS Products: A Developer’s Guide to Growing Without Breaking
When you’ve spent a decade wrestling with SaaS codebases, you start to see scalability as more than a buzzword—it’s a mindset, a set of architectural habits, and a whole lot of hard‑earned lessons from 3 a.m. production fires. Below is a practical, down‑to‑earth playbook that pulls the most useful nuggets from years of real‑world experience (and a solid DEV.to article 【1†L3-L16】). Grab a coffee, skim the headings, and keep the image placeholders for later visual flair.
1. What “Scalable” Actually Means
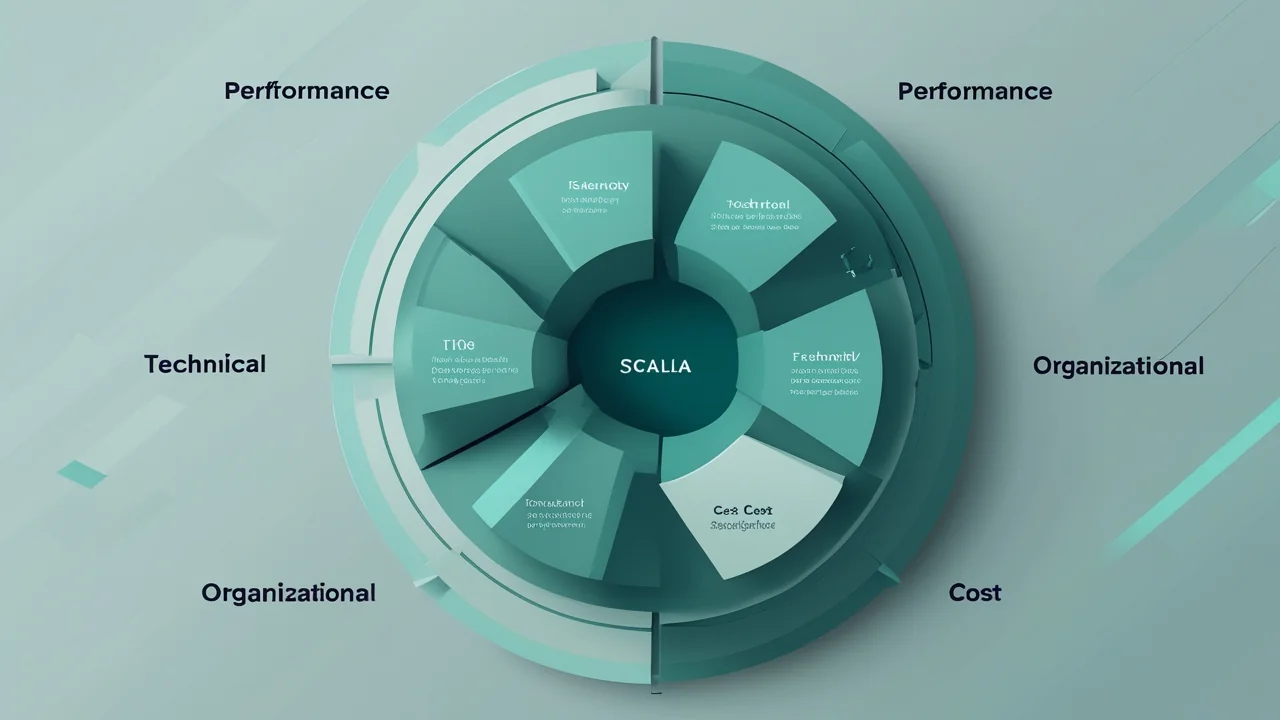
Scalability isn’t a single knob you turn; it’s a multidimensional problem that includes:
| Dimension | What to watch for | Typical pitfall |
|---|---|---|
| Performance | Keep latency low as load rises | Optimizing for speed under light load but blowing up at 10 k concurrent users |
| Technical | Codebase, CI/CD, test suite | Monolith becomes a deployment nightmare as the team grows |
| Organizational | Teams can ship independently | “Deployment day” once a week because pipelines are fragile |
| Cost | Spend sub‑linearly with users | Doubling users doubles the AWS bill |
Understanding these layers helps you avoid the classic mistake of “just add more servers” 【1†L10-L15】.
2. Architecture Foundations: Monolith First, Microservices Later
Pro tip: Start with a well‑structured monolith. It’s faster to ship, easier to debug, and lets you focus on product‑market fit 【1†L145-L152】.
When to stay monolithic
- Domain model is still fluid.
- Team size < 10 engineers.
- You need rapid iteration.
Signs you need to split
- Deployments take > 30 minutes.
- Multiple teams constantly step on each other’s code.
- Clear, stable business boundaries emerge (e.g., billing, user‑profile).
If you do split, align services with business capabilities, not technical layers 【1†L177-L182】. A “user‑management service” is far better than a generic “validation service”.
3. Database Strategy from Day One
Choose the right engine
- PostgreSQL is a solid default for most SaaS workloads 【1†L191-L196】.
- Use a document store (MongoDB) only if your access pattern truly fits key‑value lookups.
Schema & indexing tricks
- Avoid
SELECT *– fetch only needed columns 【1†L823-L825】. - Use composite indexes for common multi‑column filters 【1†L1268-L1270】.
- Denormalize when a query would otherwise join > 3 tables 【1†L210-L213】.
Read‑replicas & sharding
- Most SaaS apps are read‑heavy; add read replicas early 【1†L399-L407】.
- Sharding is a last resort; try scaling a single PostgreSQL instance first 【1†L489-L492】.
4. Caching: The Low‑Hanging Fruit
“There are only two hard things in CS: cache invalidation and naming things.” — Phil Karlton
- HTTP level – proper
Cache‑Control, ETag, and a CDN (CloudFront, Fastly) 【1†L227-L230】. - Application level – Redis or Memcached as a cache‑aside layer 【1†L232-L236】.
- Local in‑process cache for per‑request memoization 【1†L265-L268】.
Invalidation pattern:
// Pseudocode for cache‑aside with event‑driven invalidation
await redis.set(key, data, 'EX', ttl);
await messageQueue.publish('user.updated', { userId });When the user.updated event fires, a worker clears the stale key. This avoids the dreaded “stale profile after update” bug 【1†L247-L251】.
5. Asynchronous Processing Makes Everything Faster
Move non‑critical work to a queue (RabbitMQ, SQS, Redis + Sidekiq). A typical flow:
- API receives request → writes a job record → enqueues job ID.
- Worker picks up job, processes, updates the record.
Make jobs idempotent—use a unique constraint and transactional check to avoid double‑charging customers 【1†L306-L313】.
6. API Design for Scale
- Version from day one (
/api/v1/...). - Rate limit early (e.g., 1 000 req/hr per API key) 【1†L332-L335】.
- Cursor‑based pagination over offset to avoid duplicate/missing items 【1†L337-L342】.
- Partial responses (
fields=id,name) for mobile bandwidth savings 【1†L350-L353】.
7. Stateless Authentication
Sticky sessions are a nightmare at scale. Prefer JWTs for stateless auth, or store sessions in Redis if you need server‑side revocation 【1†L366-L383】. Keep JWT payloads tiny and set short expirations; use refresh tokens for longer sessions.
8. Multi‑Tenancy Patterns
| Approach | Isolation | Ops overhead |
|---|---|---|
| Separate DB per tenant | Highest | High (migration, backups) |
| Separate schema per tenant | Medium | Medium |
Shared schema + tenant_id | Low | Low (most common for startups) |
Start with the shared schema and migrate to stricter isolation only for large or regulated customers 【1†L495-L522】.
9. Infrastructure & Deployment
Containers & Orchestration
- Docker for reproducible builds.
- Kubernetes is powerful but often overkill early on; consider AWS ECS or Cloud Run for simplicity 【1†L568-L585】.
Infrastructure as Code
- Terraform modules for reusable patterns; keep state secure 【1†L608-L635】.
CI/CD Essentials
- Run tests on every commit.
- Deploy with blue‑green or rolling updates for zero‑downtime 【1†L656-L660】.
- Feature flags let you ship code without exposing it 【1†L666-L669】.
10. Observability: You Can’t Fix What You Can’t See
- Structured logs (JSON) and a central log store (ELK, Datadog) 【1†L681-L688】.
- Metrics: request latency percentiles, error rates, cache hit ratios 【1†L690-L698】.
- Distributed tracing (Jaeger, X‑Ray) once you have multiple services 【1†L703-L707】.
- Alert on anomalies, not just thresholds, to avoid fatigue 【1†L709-L713】.
11. Team & Process Scalability
- Modular code with clear boundaries (SOLID, DI) 【1†L1330-L1346】.
- Keep PRs small and review within hours.
- Automate environment setup (Docker‑Compose) for new hires 【1†L1454-L1457】.
- Document everything: architecture diagrams, runbooks, ADRs 【1†L1397-L1415】.
12. Cost Optimization at Scale
| Cost lever | How to apply |
|---|---|
| Right‑size instances | Monitor CPU, shrink under‑utilized servers 【1†L1479-L1481】 |
| Autoscaling | Scale up on spikes, down on idle periods 【1†L1482-L1484】 |
| Spot / preemptible VMs | Batch jobs, dev/test environments 【1†L1486-L1489】 |
| Tiered storage | Move cold data to Glacier or Cold Blob 【1†L549-L552】 |
| Query optimization | Faster queries = lower DB CPU cost 【1†L1512-L1513】 |
13. Real‑World Pitfalls & How to Dodge Them
| Pitfall | Symptom | Fix |
|---|---|---|
| Deployment day | Weekly manual releases, nervous engineers | Automate CI/CD, use blue‑green deployments |
| Cache stampede | Sudden DB overload after cache expiry | Use lock‑around regeneration or stale‑while‑revalidate pattern 【1†L941-L945】 |
| N+1 queries | DB CPU spikes under load | Enable eager loading or DataLoader (GraphQL) 【1†L820-L828】 |
| Legacy monolith | New features take forever to ship | Strangler‑fig pattern: route new work through micro‑services while keeping old code alive 【1†L1814-L1816】 |
14. Frequently Asked Questions
Q: When should I start sharding?
A: Only after you’ve exhausted read‑replicas, tuned indexes, and confirmed that a single primary can’t handle write throughput 【1†L438-L447】.
Q: Is GraphQL worth the added complexity?
A: For APIs with many optional fields or heavy mobile usage, yes—just add query‑complexity limits to avoid expensive nested queries 【1†L1660-L1668】.
Q: Do I need a service mesh?
A: Only when you have > 20 services and need advanced traffic routing, retries, and mTLS. Otherwise, stick with simple load balancers 【1†L1750-L1765】.
15. TL;DR Checklist for a Scalable SaaS Launch
- Start with a modular monolith; keep it clean.
- Pick PostgreSQL + Redis early; design schema for read patterns.
- Cache aggressively (CDN, HTTP, Redis).
- Offload heavy work to message queues; make jobs idempotent.
- Version APIs, paginate with cursors, and rate‑limit.
- Use JWTs or centralized session store; avoid sticky sessions.
- Deploy via IaC + CI/CD with zero‑downtime strategies.
- Instrument logs, metrics, and traces; set smart alerts.
- Automate onboarding, documentation, and runbooks.
- Continuously monitor cost per request and right‑size resources.
16. Closing Thought
Scalability isn’t a one‑off project; it’s a continuous practice of measuring, iterating, and simplifying. As you grow from a handful of users to millions, the fundamentals—solid data modeling, thoughtful caching, reliable automation, and a collaborative team culture—stay the same. Master those, and the rest (Kubernetes, serverless, service meshes) will just be tools you can pick up when the time is right.
Happy building, and may your SaaS scale like a well‑engineered rocket—steady, predictable, and with a smooth launch every time. 🚀

[IMAGE:Cost‑optimization dashboard showing CPU, storage, and network spend]